1、Windows安装pyspark
采用cursor+conda演示,使用python venv 可参考macos
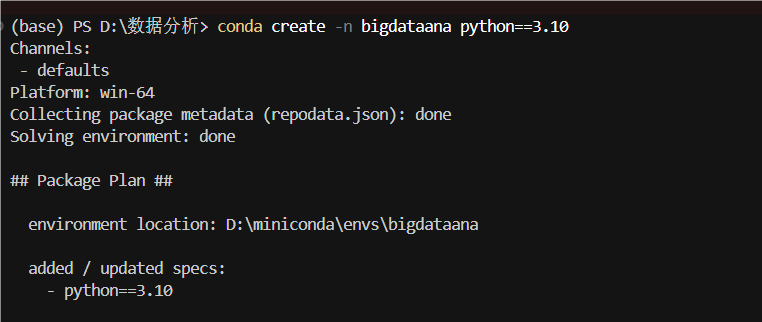
1.1 新建一个conda环境,安装pyspark,建议安装spark3.0
conda create -n bigdataana python==3.10
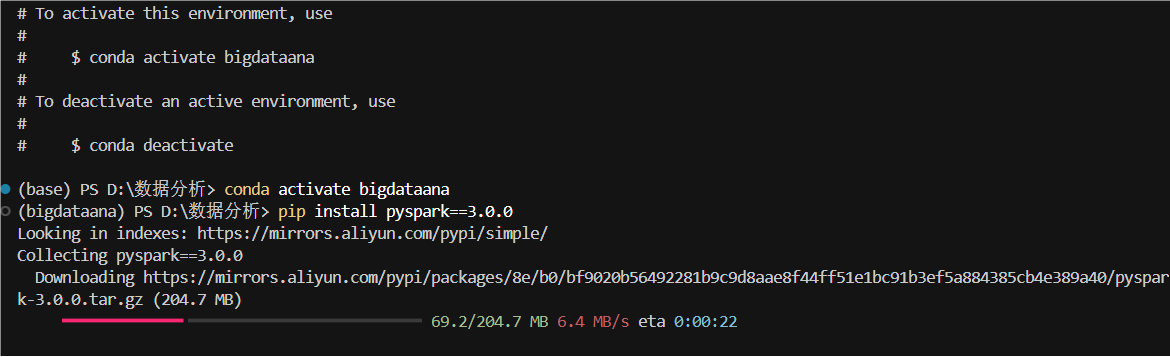
conda activate bigdataana
pip install jupyter pandas pyspark==3.0.0
1.2 安装openjdk
在下面网站下载https://jdk.java.net/archive/,下载后解压到你的安装软件的目录。

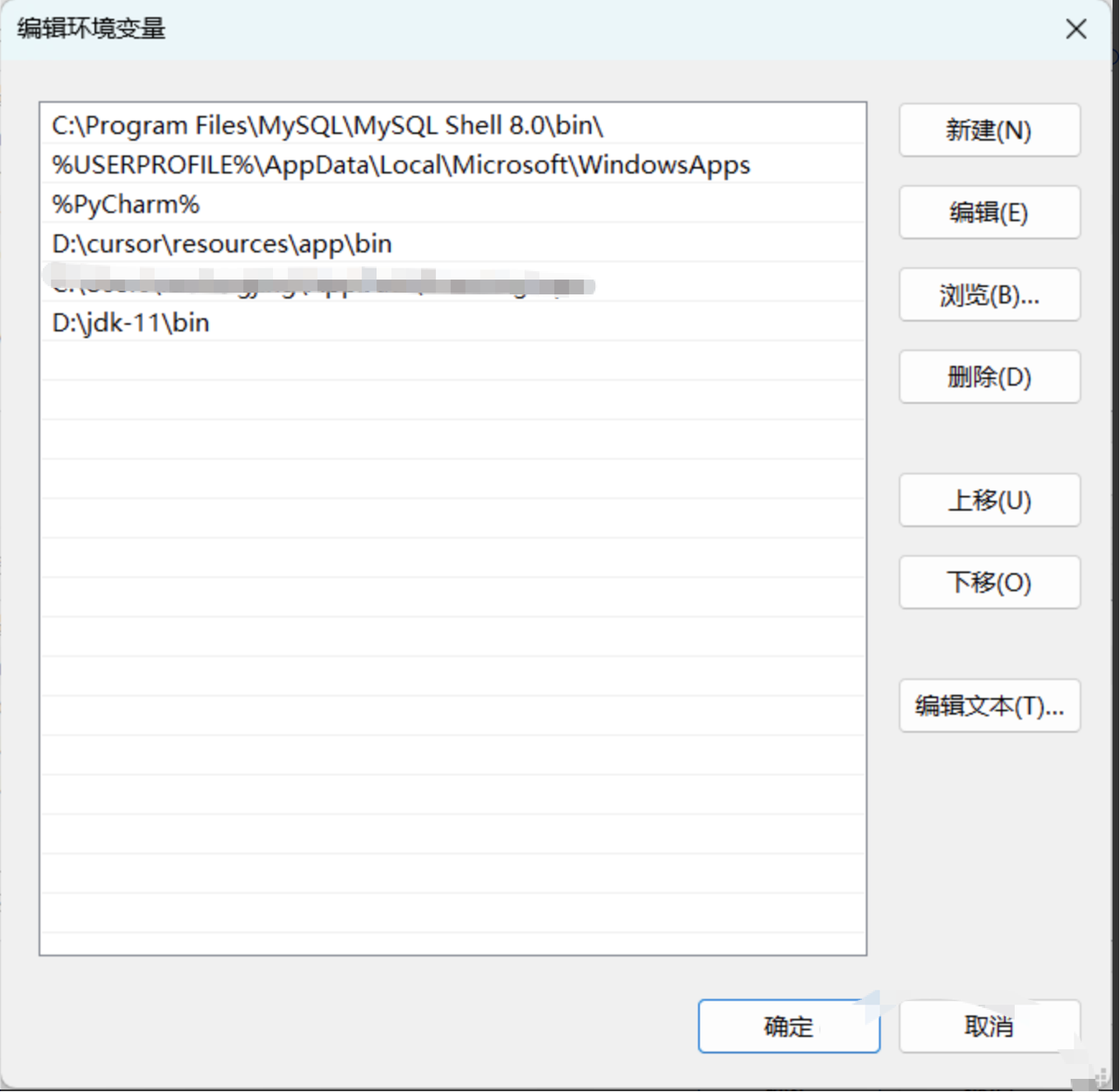
1.3 添加环境变量
根据你自己选择在用户或者系统添加java的bin目录,图中是添加的用户变量(系统设置-添加环境变量)。
1.4 创建spark会话,本地访问spark-UI
建议退出cursor重进,使得java环境变量生效。运行下面代码:
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("model_predict_for_sql_construct") \
.master("local[*]") \
.config("spark.ui.port", "4040") \
.getOrCreate()
如果执行成功,就可以在浏览器看到spark-UI界面啦:
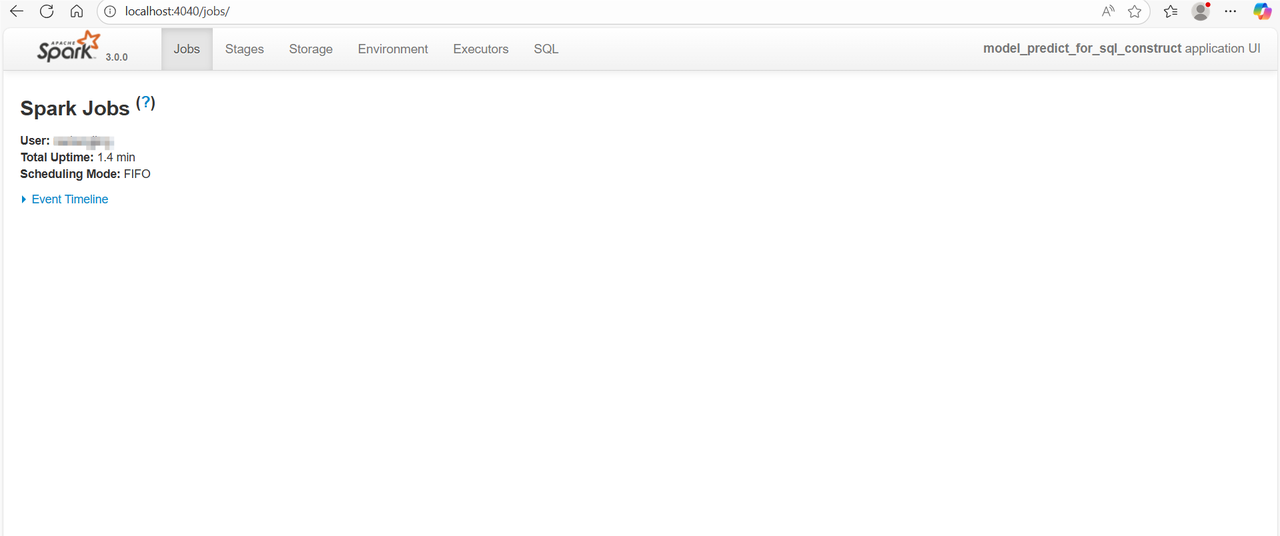
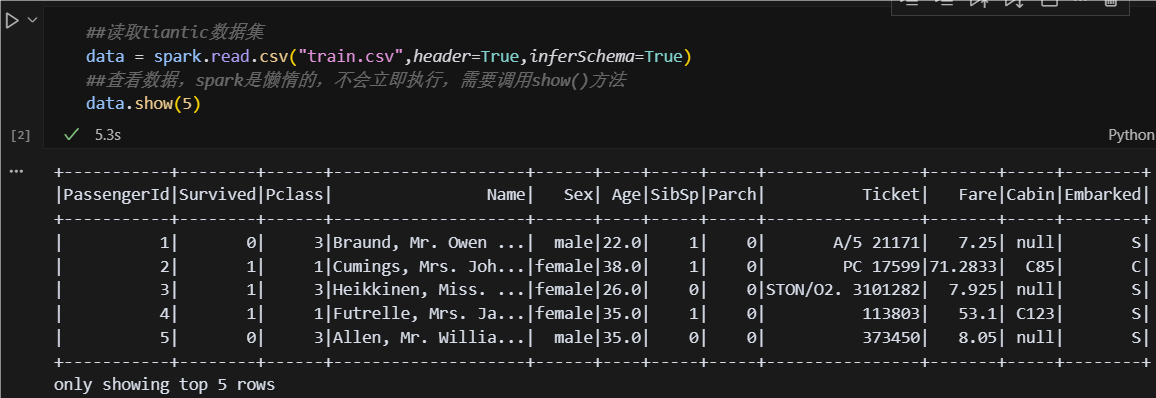
接下来开始运行代码,读取你的数据集!如果你发现有不会的,add to cursor chat ,学会把AI用起来!!!
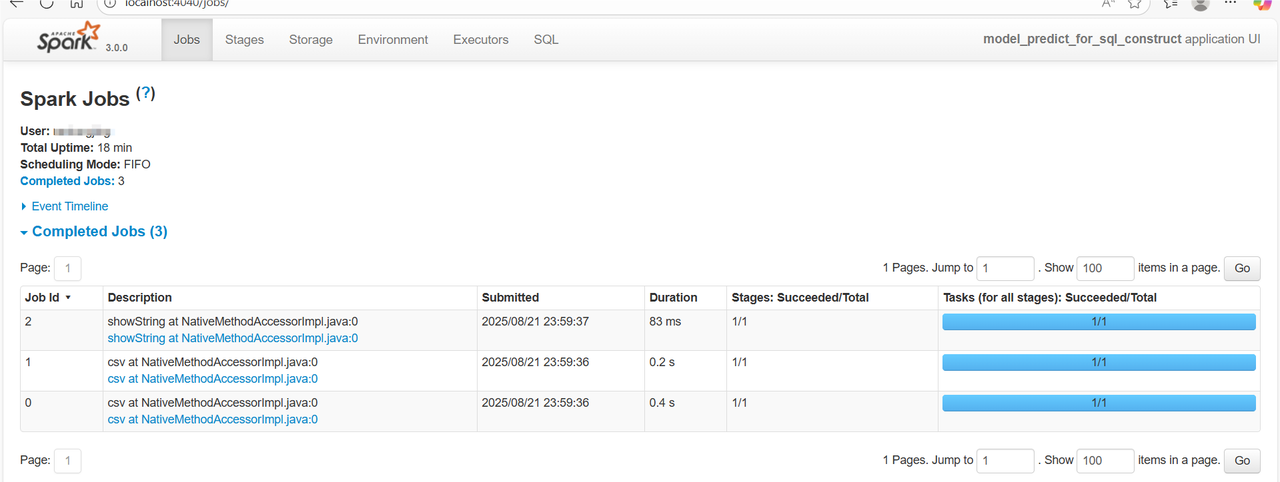
打开UI查看,你的任务就有执行啦,探索一下,不懂问ai:
1.5 开始使用SQL进行分析!
使用sql前,需要将你读取的数据注册为视图,然后根据视图来查询,视图可以理解为:数据库表名。

注册视图后,就可以在sql中引用了,开始数据探索!
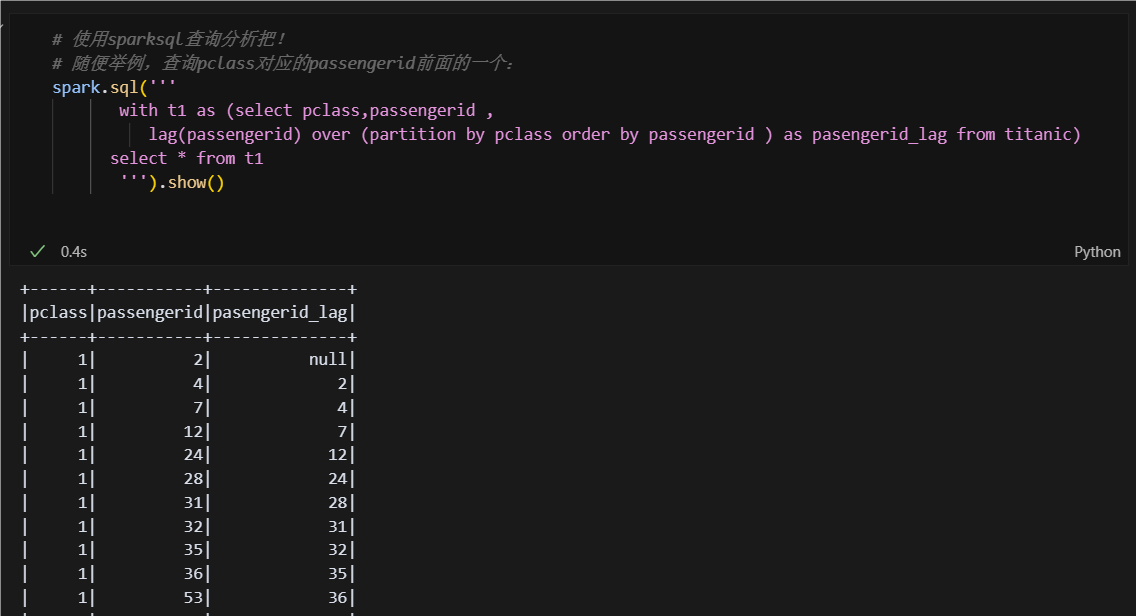
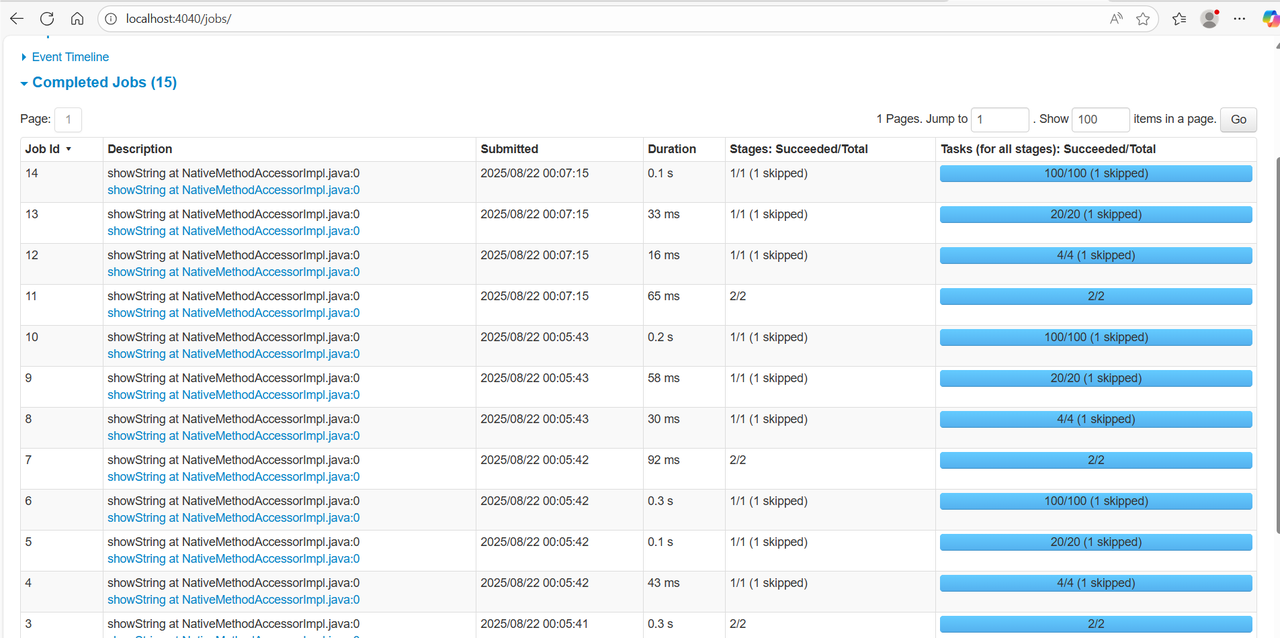
在spark-UI中也可以监控内容:
2、MAC安装pyspark
采用cursor+python venv演示,使用conda可参考windows
2.1 安装python ,激活进入对应的环境。安装pyspark,建议安装pyspark==3.0
如果你使用了conda环境,那就直接切换到conda环境进行安装就好了,无需创建python虚拟环境。

2.2 安装openjdk
推荐安装openjdk11,网站:https://jdk.java.net/archive/
终端运行java --version,如果发现下面的问题,可以参考下面的解决方案:
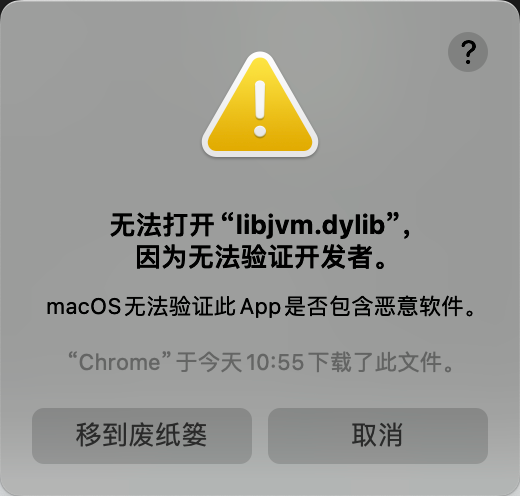
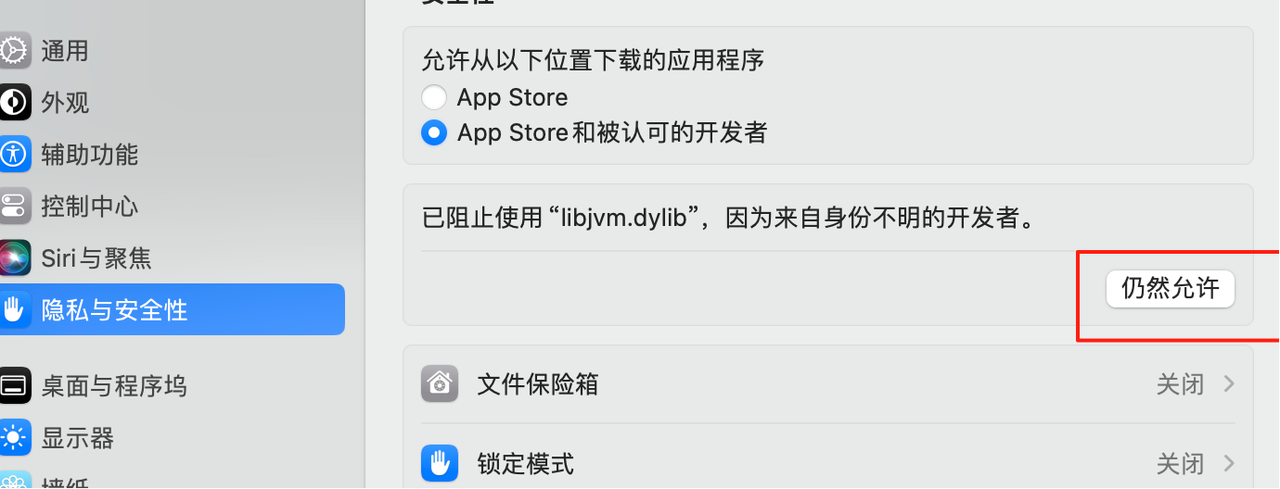
或者在终端使用如下命令,可以解除所有的限制,建议使用正常后,将安全禁用重新打开。
sudo spctl --master-disable #这将禁用 macOS 的 Gatekeeper,允许所有应用程序运行。
sudo spctl --master-enable # 请注意,禁用 Gatekeeper 会降低系统的安全性,因此建议在可以运行后重新启用。

2.3 新建jupyter notebook,内核选择你带有pyspark的python内核
编写以下代码:
# 如果你的系统已经有java的环境变量了,那就不用设置了,如果报错,可以设置下。
import os
os.environ['JAVA_HOME'] = '/Users/xxx/jdk11/Contents/Home'
os.environ['PATH'] = '/Users/xxx/jdk11/Contents/Home/bin:' + os.environ['PATH']
# 创建spark会话
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("model_predict_for_sql_construct") \
.master("local[*]") \
.config("spark.ui.port", "4040") \
.getOrCreate()
当出现下面的日志时,说明成功了,在浏览器打开localhost:4040 webUI界面,即可看到spark任务。
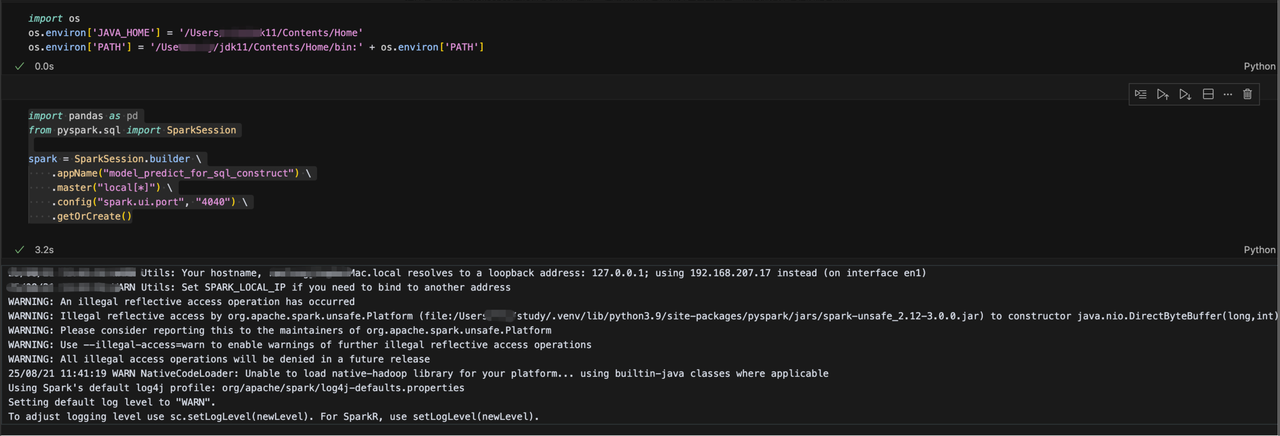
后面的步骤就如同windows一样啦,注册视图,开始sql分析!!!
评论 (0)
评论需要管理员审核后才能显示,请文明发言
加载评论中...